-

理学院何佳清团队在science发表高熵热电材料研究论文
-

理学院院长杨学明院士获“未来科学大奖”
-
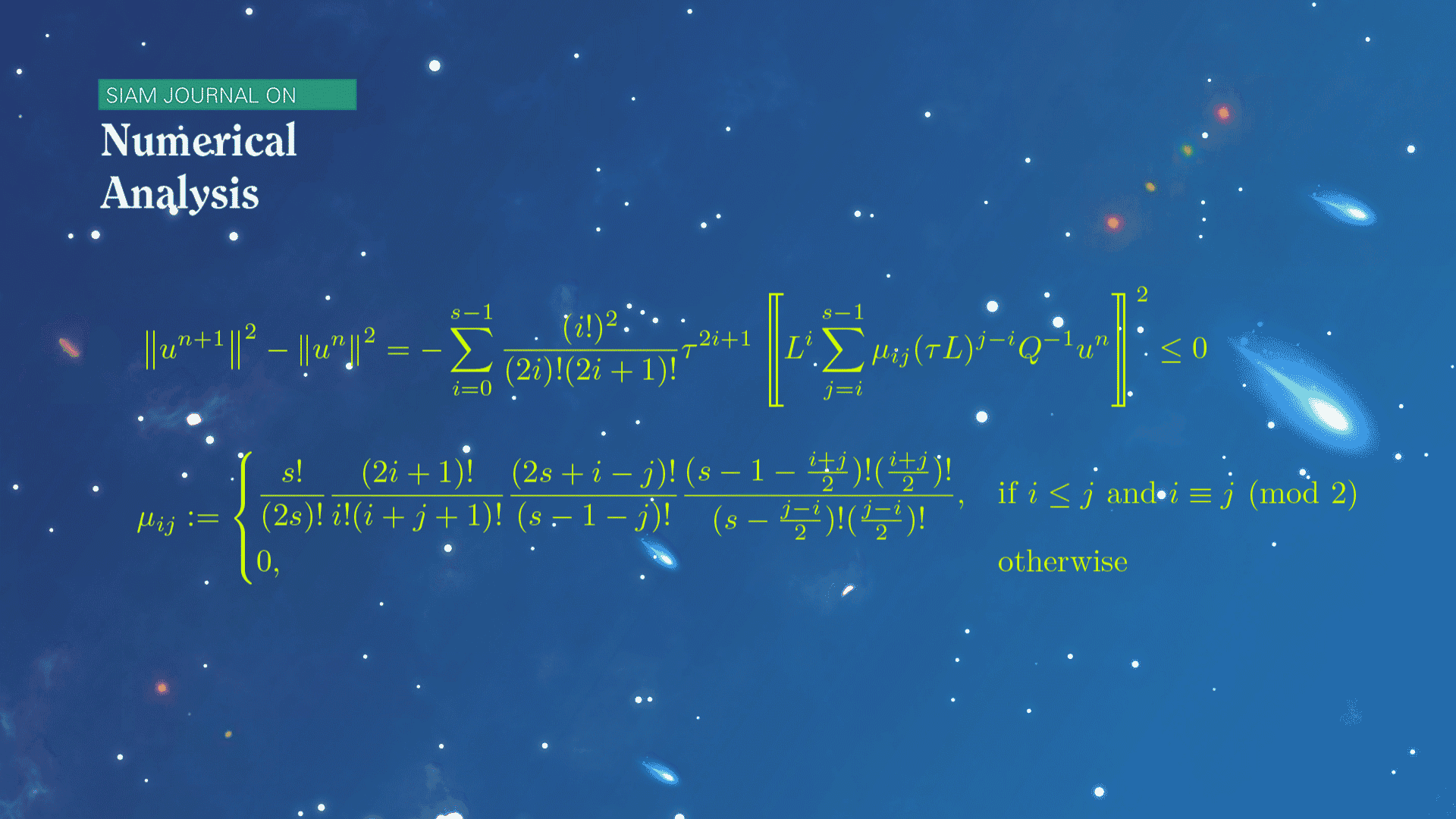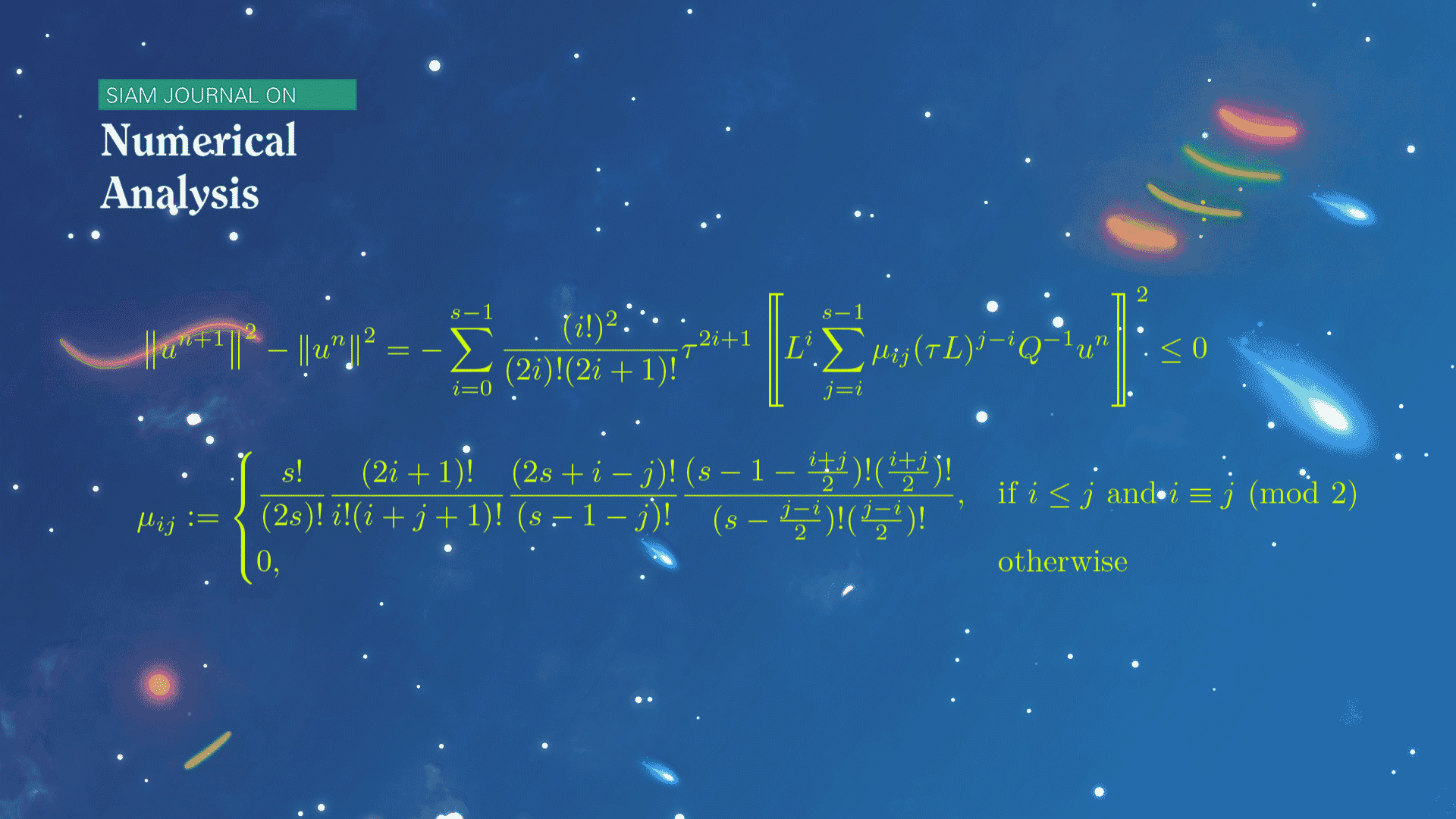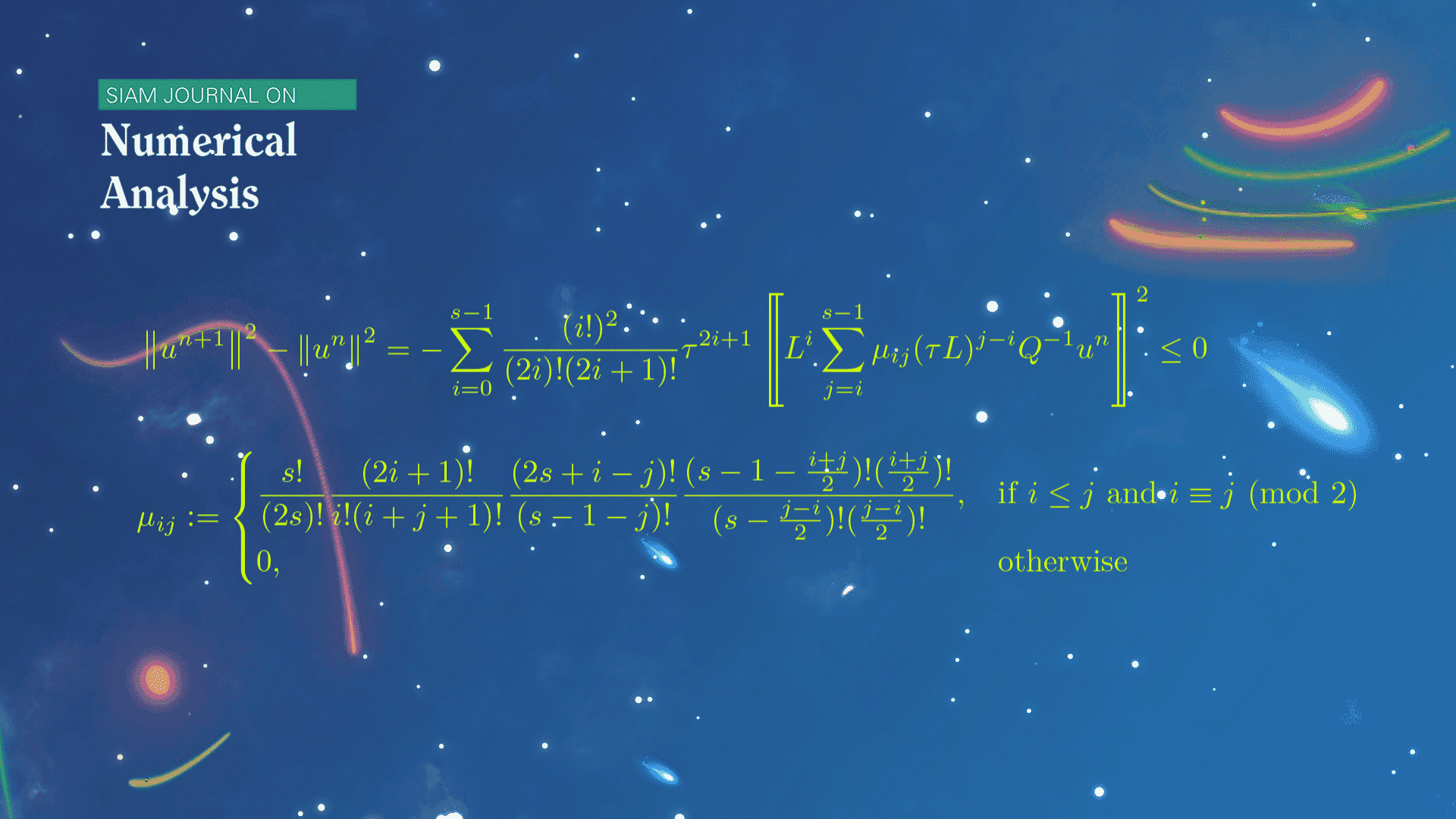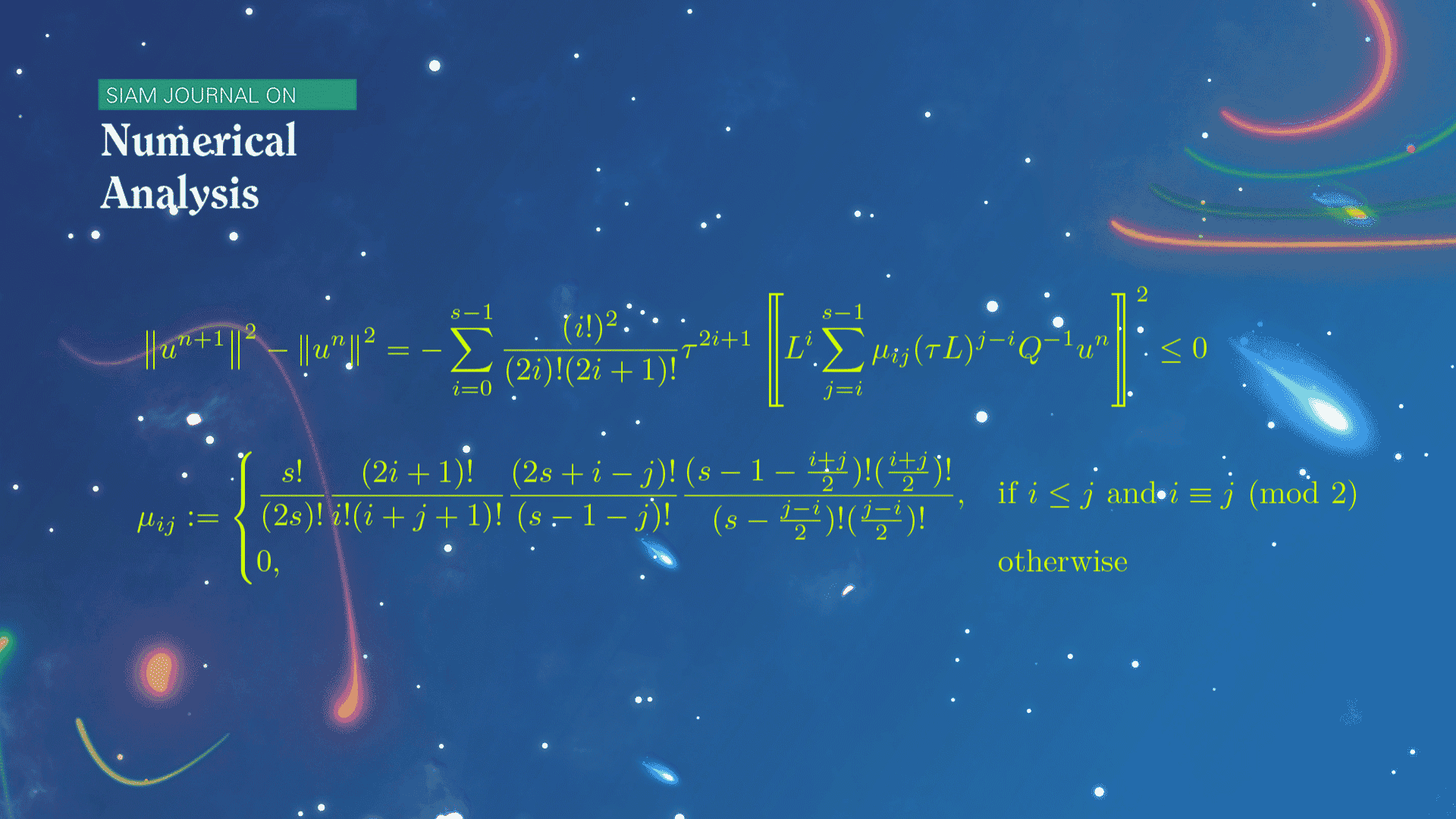
数学系本科生魏元哲等在龙格-库塔(Runge-Kutta)方法的稳定性研究方面取得新进展
-

理学院杨英杰、陈晓非在 Science发表关于流星撞击火星研究的评述文章
-

南科大柳卫平团队与合作单位联合在nature发文揭示古老恒星钙丰度之谜
-

前沿灼见向未来——“化学反应的量子特性”学术报告会在南科大召开
-

理学院范靖云课题组关于“复数的根本地位”的研究成果入选2022年国际物理学十大进展
-

理学院殷嘉鑫在Nature撰写笼目晶体综述
-
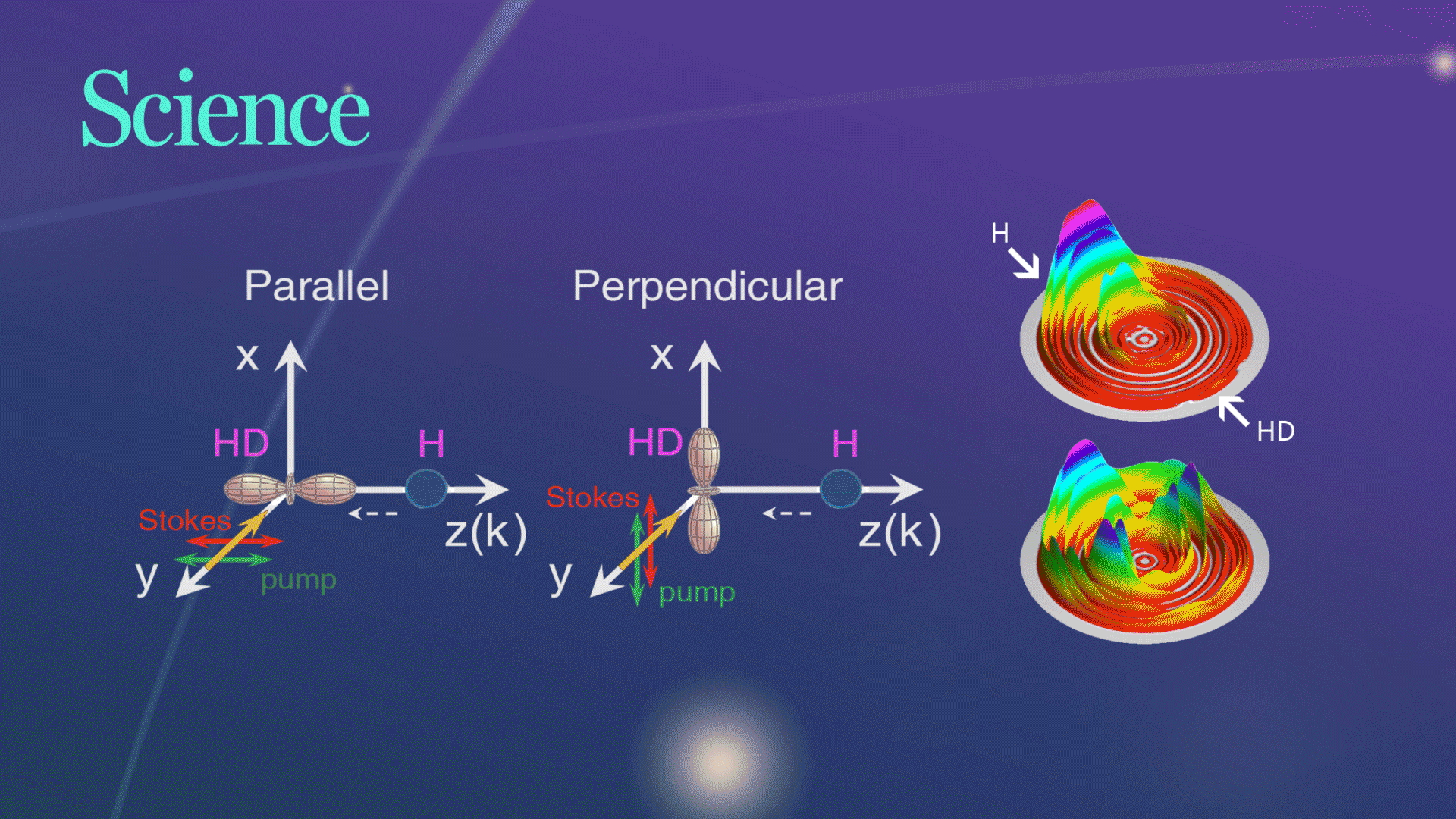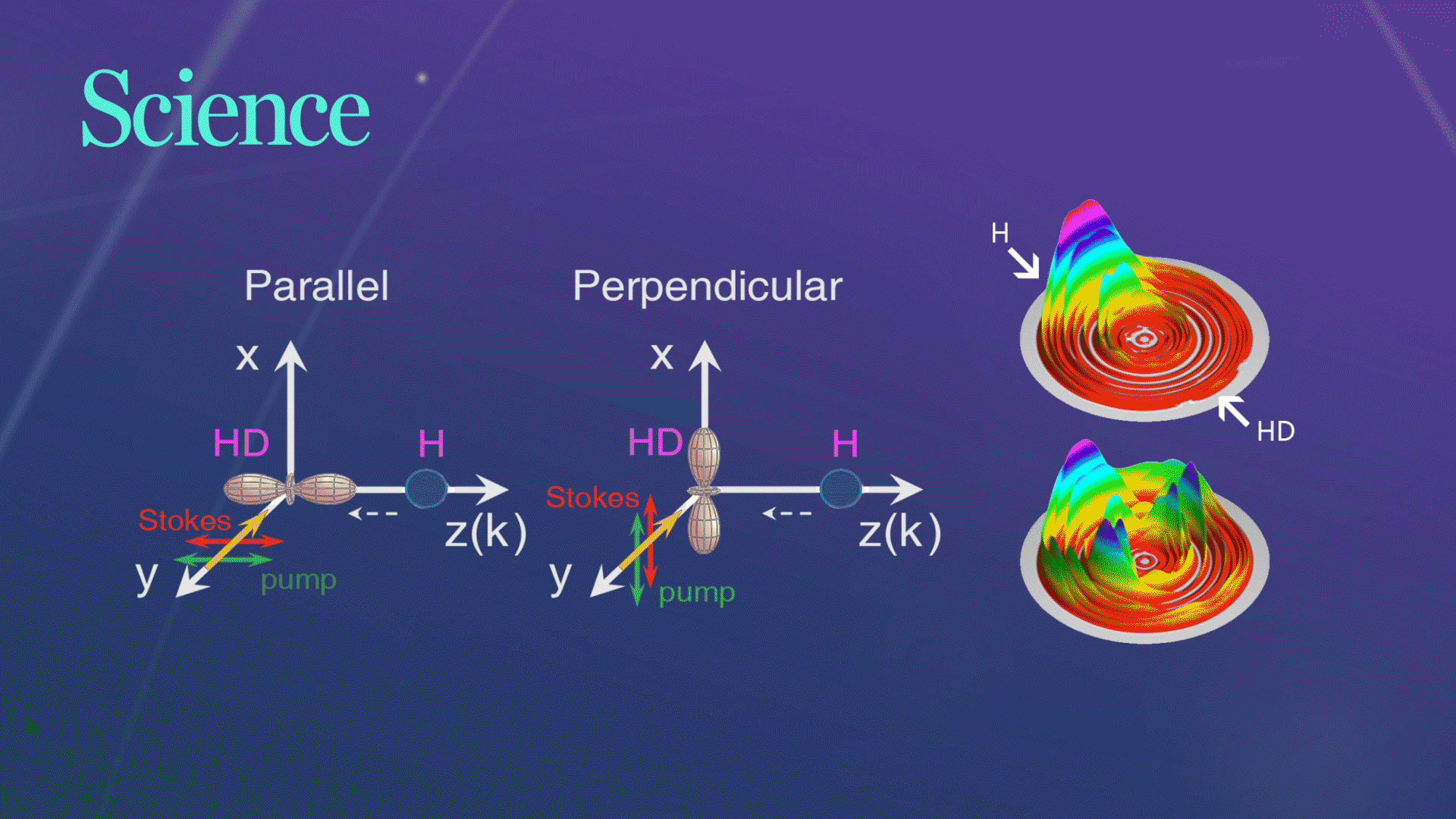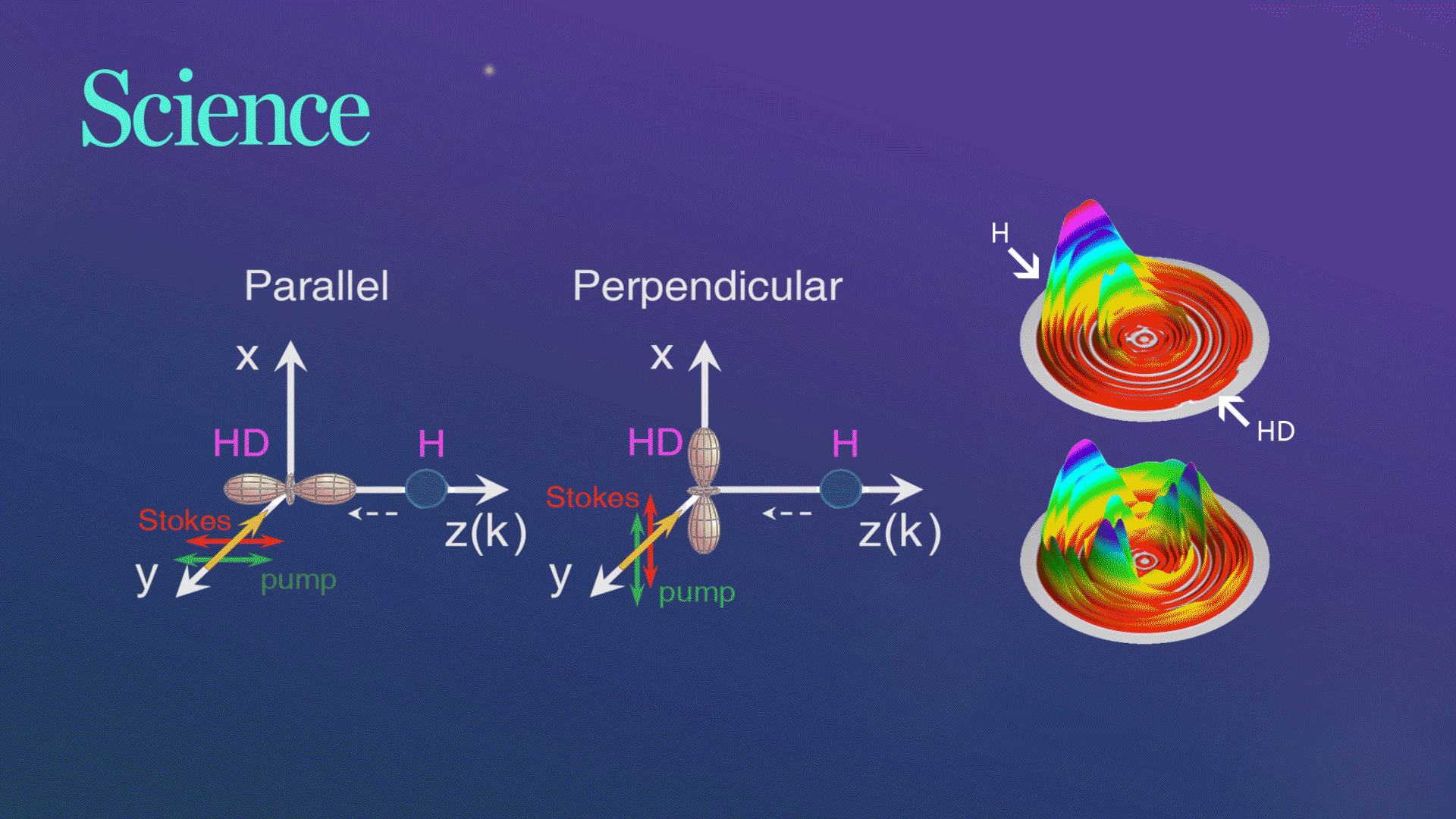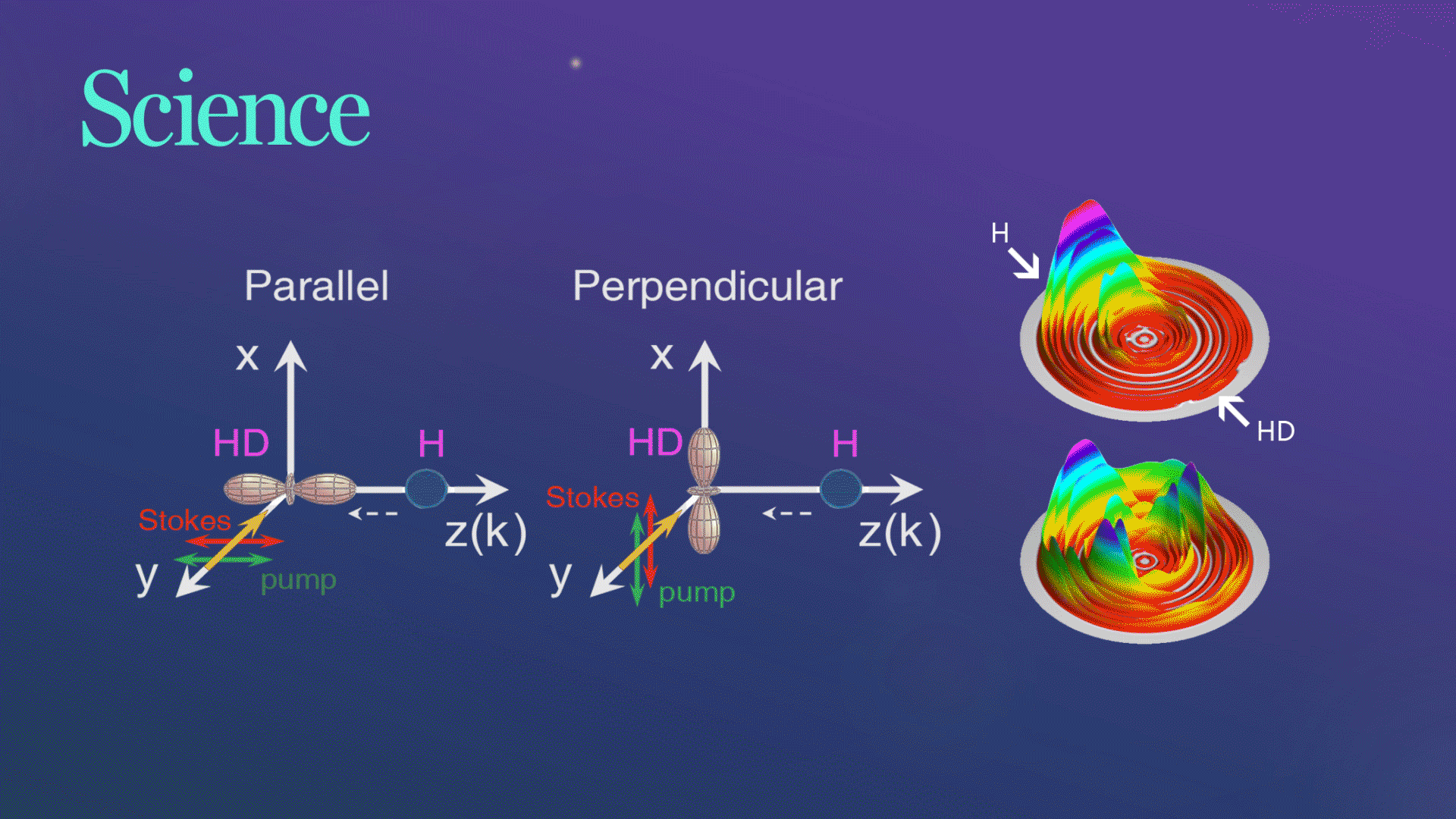
Science发文!杨学明院士团队合作实现化学反应的立体动力学精准调控
-

理学院讲席教授埃菲·杰曼诺夫与师生分享学术之路
-
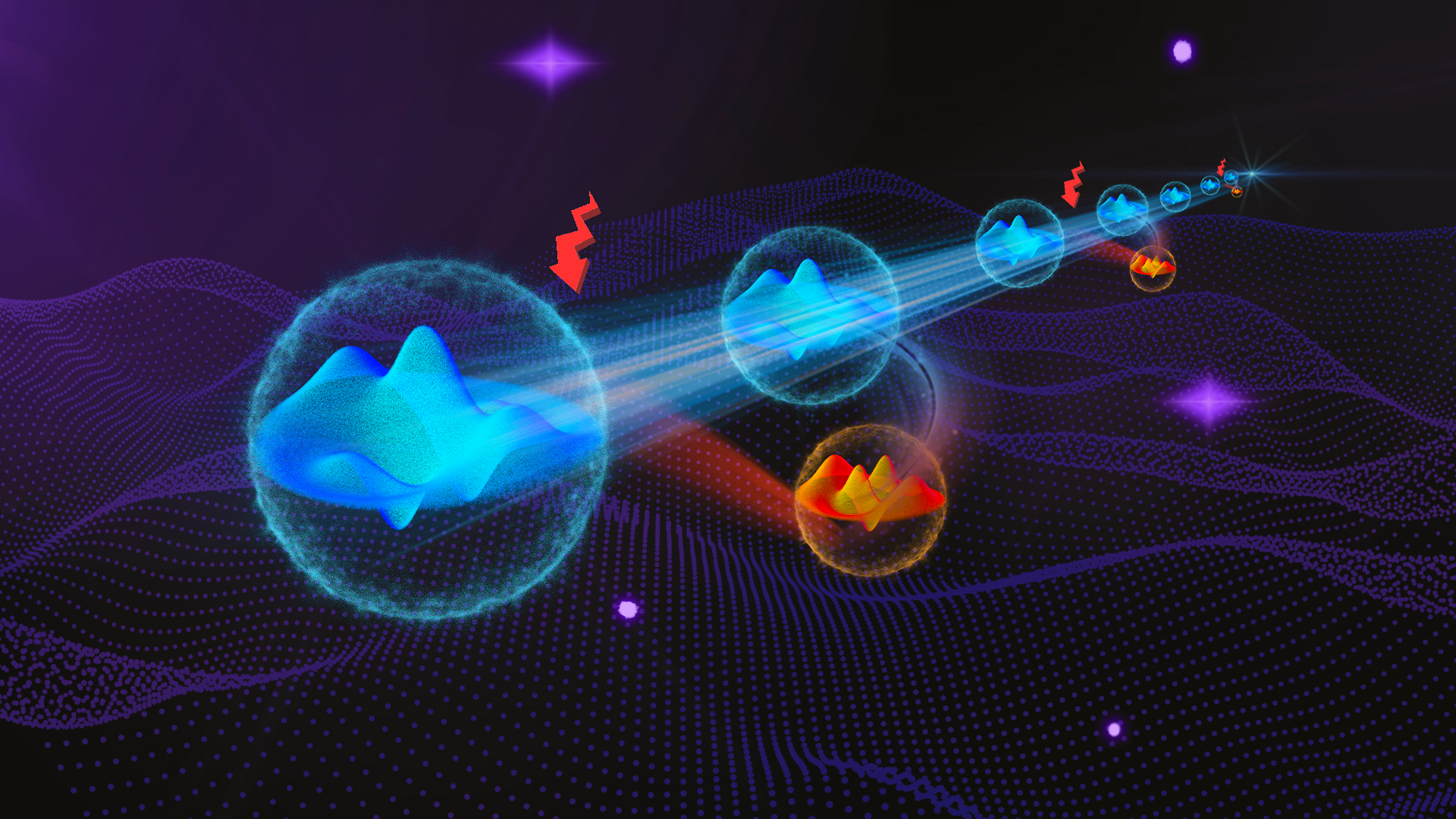
Nature发文!俞大鹏院士课题组联合团队发文展示量子纠错优势
-

Nature+1!化学系刘心元团队在立体汇聚式N-烷基化领域中取得重要进展
-
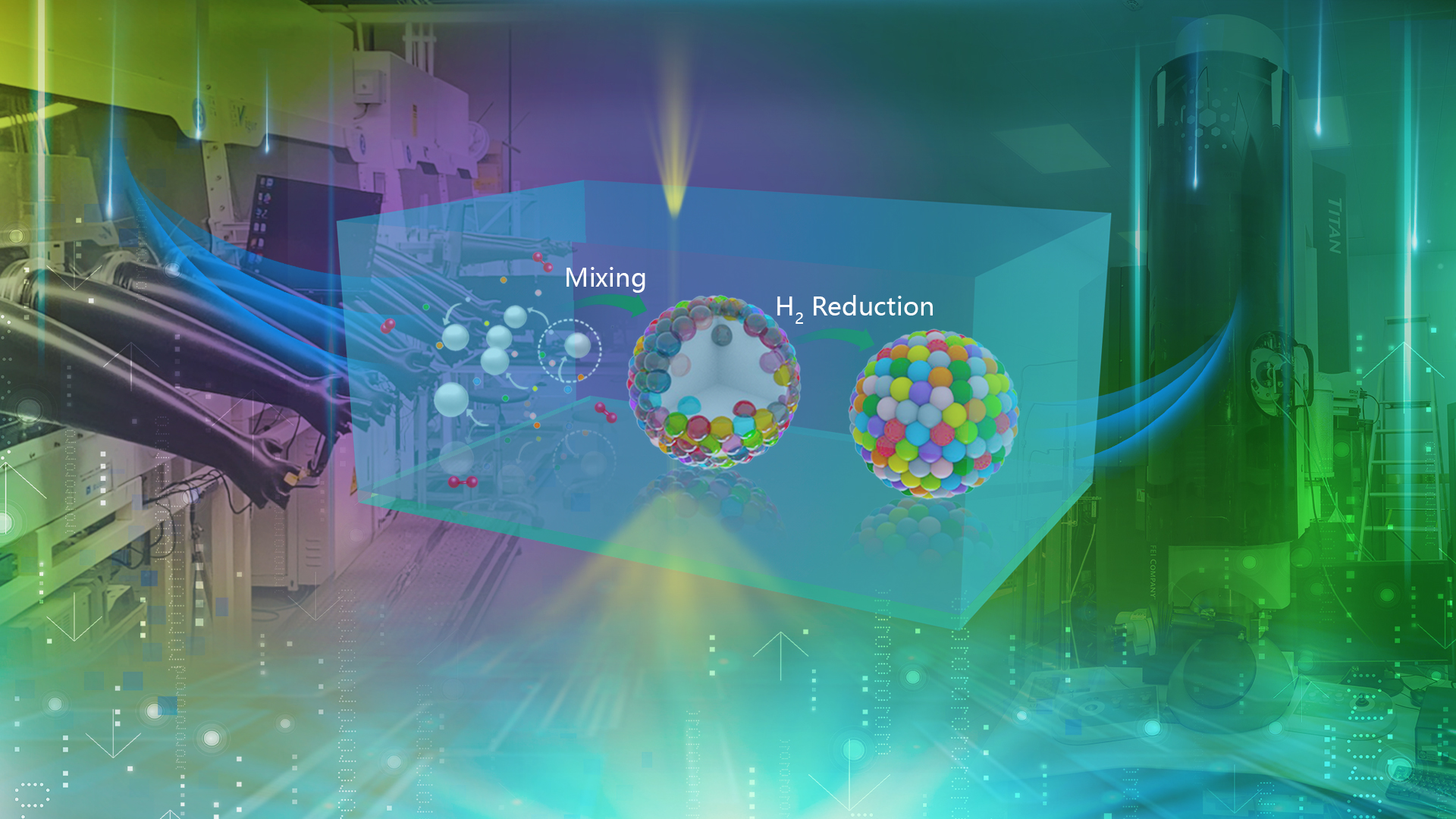
理学院林君浩团队合作在Nature发表有关高熵合金纳米颗粒合成与生长机理的研究成果
-

南科大刘心元获第五届“科学探索奖”
-

理学院刘柳团队在Science发文揭秘反电子态双亲性卡宾
-

南科大俞书宏院士团队在Science发文 提出耐疲劳结构材料领域取得新策略
-
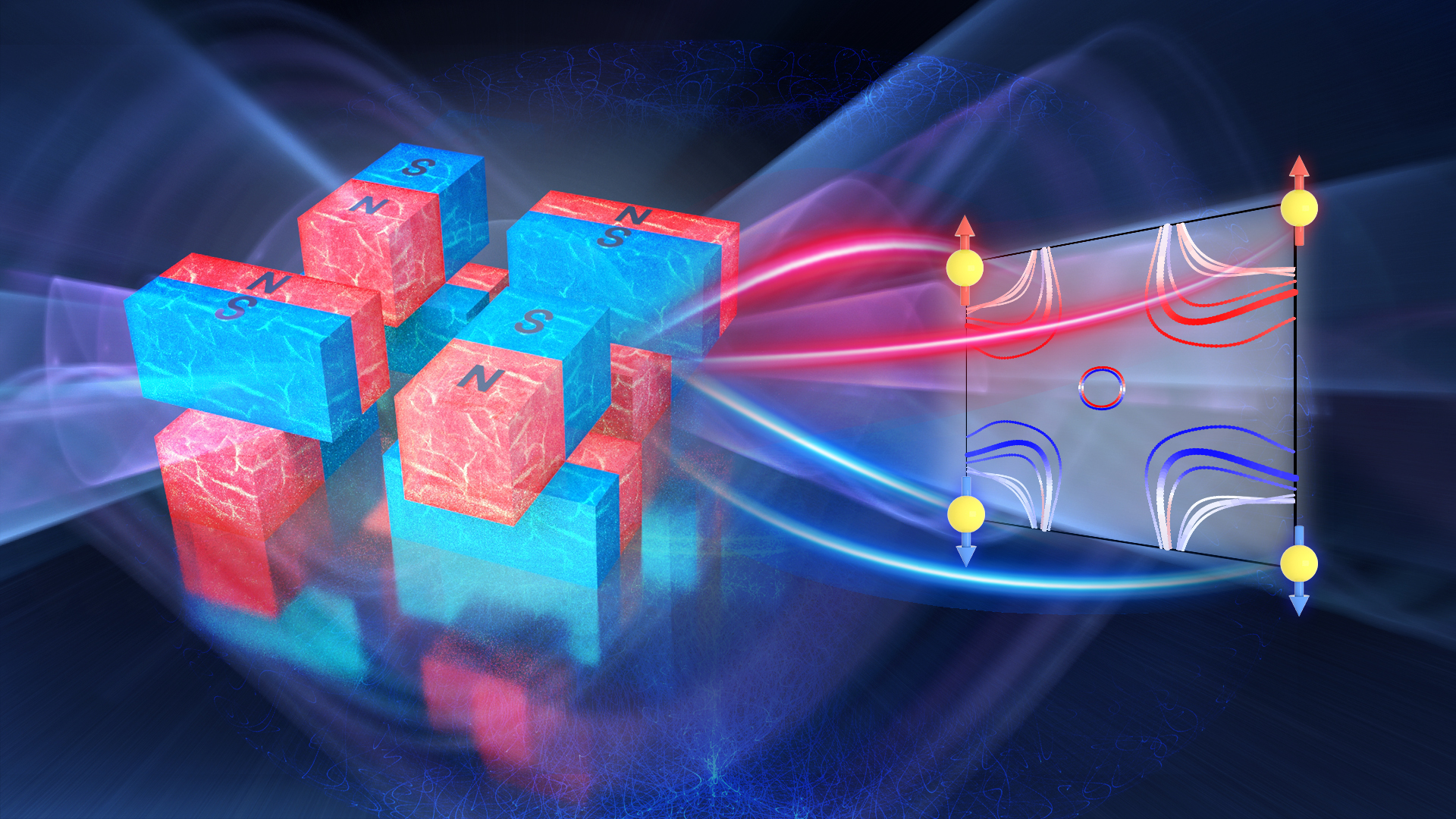
理学院刘畅、刘奇航课题组在Nature发表反铁磁材料自旋劈裂行为的研究成果
-

杨学明院士团队合作发现首例分子高激发态的漫游反应通道 成果登上Science



